
AI Document Summarizer
We’ve all been there, staring at lengthy business documents, legal contracts, policy papers, or academic articles. At some point, we’ve all silently acknowledged some of their content without actually reading them, haven’t we? It often feels more like a chore than a task. If you're anything like me, you've probably felt overwhelmed by the sheer volume of text and wished for a smarter way to get to the point quickly.
But what if you could summarise those documents in just seconds that too without sending any sensitive information to the cloud? Sounds too good, doesn’t it?
We’re not just imagining this. it’s already happening.
A Little History :
In early 2023, Meta released the LLaMA models. Unlike previous large models, LLaMA was relatively compact and efficient, which opened the door for people to explore running it outside traditional cloud environments.
Then came a breakthrough. In March 2023, developer Georgi Gerganov launched llama.cpp, a C++ port that made it possible to run these models entirely on local CPUs, even on laptops. No GPU. No internet. No cloud. This was a game changer. Suddenly, running an LLM became as simple as opening a desktop application.
Soon after, tools like GPT4All and Text Generation WebUI emerged, offering graphical interfaces to make the experience even smoother, especially for non-technical users. As these early tools began to gain momentum, it became clear that running large language models locally was not only possible but increasingly practical.
Ollama :
Ollama is one such tool that brings all the benefits of privacy, speed, and offline capability into an incredibly simple, developer-friendly experience. With a single command, you can run models like LLaMA 2, Mistral, or Gemma without needing to worry about configuration, model formats, or environment setup. It even comes with a local API, making it easier to plug AI directly into your workflows or applications.
Of course, choosing the right model depends on your use case. Factors like model size, number of parameters, and available system resources all play a role. But the future of AI isn’t only on the cloud, it’s also on your laptop.
But why should anyone go for a local machine? Is the Cloud not secure enough?

But Why Go Local? Isn’t the Cloud Secure?
Yes, the cloud is secure, but "secure" doesn't always mean "private," "affordable," or "fully under your control."
Here’s why local models are gaining attention:
Data Privacy: Nothing leaves your machine. Sensitive documents stay local.
Cost Efficiency: No pay-per-token charges. No API rate limits.
Speed: No internet round-trips. Responses are near-instant.
Offline Access: Works even with no connectivity.
Customization: You're free to tweak, fine-tune, or even swap out models.
Running LLMs locally empowers you with full control, something the cloud often abstracts away.
What are we building?
Let me now get to the point. Let us learn how to create a document summarizer that :
Loads a PDF file
Extract its text
Sends it to a locally running LLM
Outputs a clean, easy-to-read summary
Pre-requisites:
Python 3.7+
Ollama installed on your machine (download here)
A pulled model - Am using Mistral, you can use any model of your choice. You can refer to Ollama’s website.
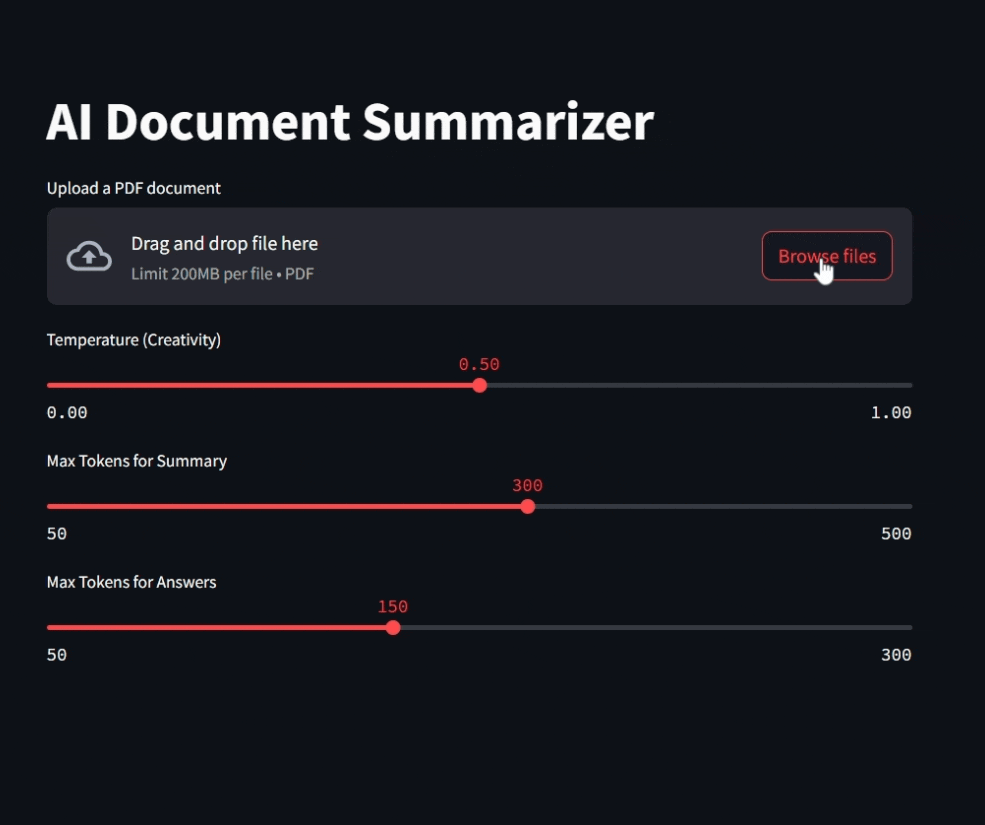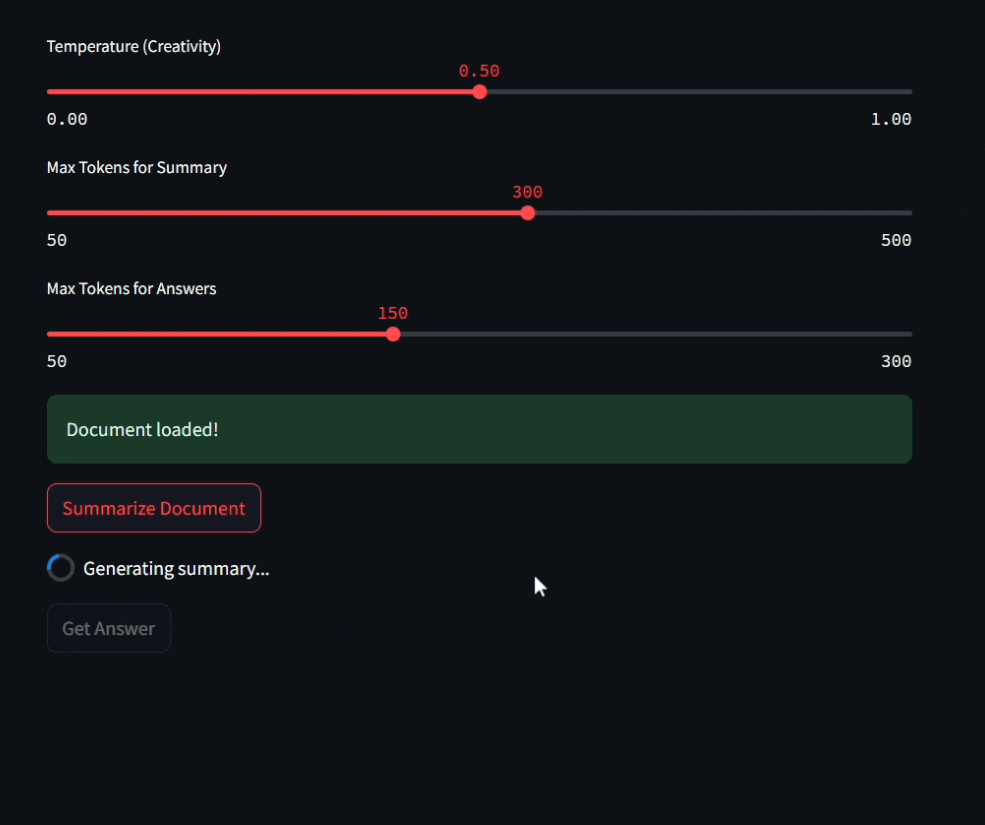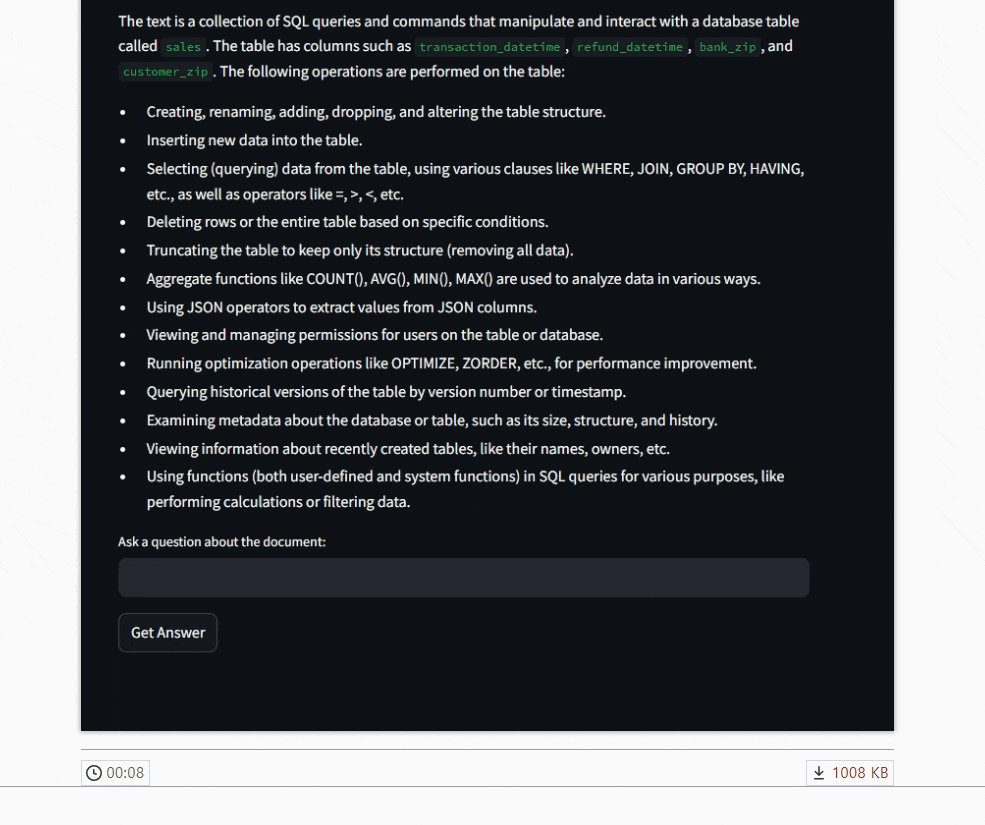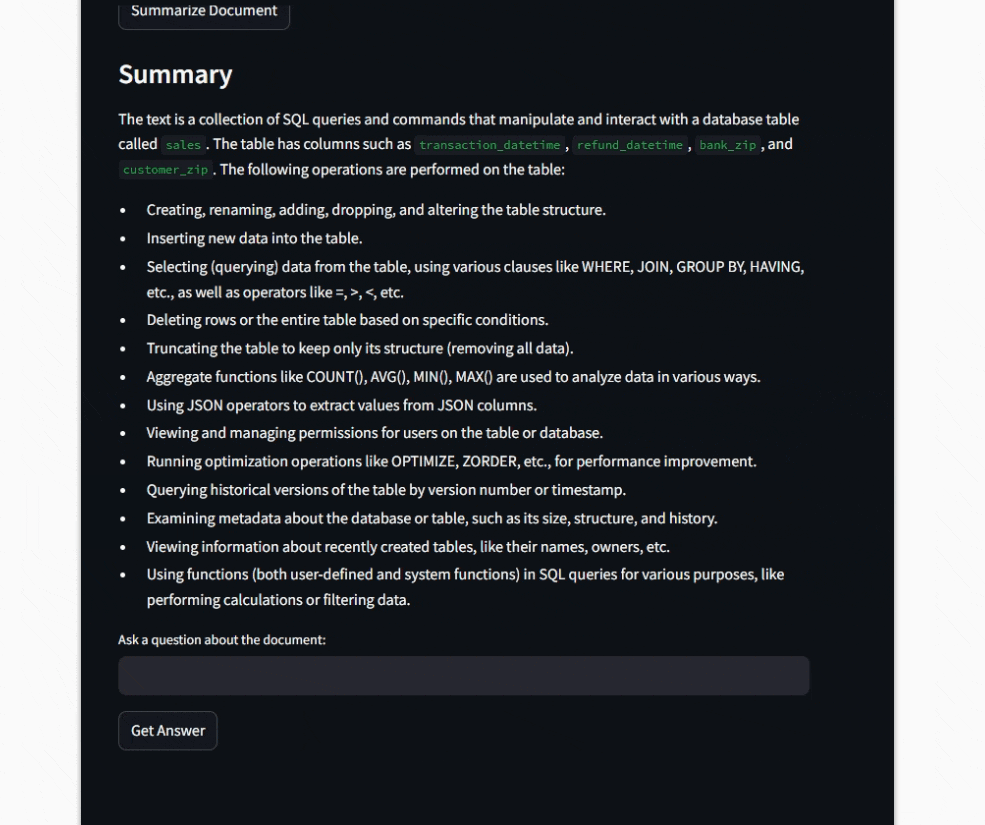
The Python code builds a Streamlit web app (you could use Gradio too) that lets users upload a PDF and interact with its contents. It uses the PyPDF2 library to extract text from the uploaded file. Two main functions: summarize_text() and ask_question(), send prompts to a locally running Mistral model via Ollama using a REST API.
http://localhost:11434/api/generate is the REST API endpoint provided by Ollama that accepts requests for generating text using the selected model (e.g., Mistral in my case).
Users can adjust parameters like temperature and token limits using sliders(more detailed explanations for this are here). The code handles UI logic for file upload, summary generation, and question answering, making the app responsive and easy to use.
Wrapping up:
I hope this has given you a basic idea of how we can run the models locally while maintaining data privacy and gaining full control over the model behaviour using parameters, all while keeping the experience smooth and minimal. As you’ve seen, with tools like Ollama, it’s easier than ever to experiment with powerful open-source models on your machine. The full working version of the code is here, take a look or experiment with it.