
Generative AI Made Simple

Have you ever picked up a new programming language or tool and found yourself overwhelmed by a wave of unfamiliar jargon? You’re not alone. The first few encounters with new technical concepts can feel intimidating. However, just like learning any skill, once you grasp the fundamentals, everything starts to fall into place. In my blog post today, we are aiming to do that: simplifying the often intimidating world of Generative AI.
If you are not building your own AI models or frameworks, you might be asking:
Do I really need to understand these technical concepts?
It’s a fair question. After all, you don’t need to be a physicist to enjoy the game of pool. You don’t calculate the angle of impact or friction coefficients before making a shot. You just learn by playing, and over time, your intuition just guides you.
The same goes for AI. While you don’t need a PhD in ML to use or benefit from generative AI tools, understanding a few foundational concepts can help you make better sense of the outputs you can get and even steer them more efficiently.
Why does Generative AI feel confusing?
At its core, computers understand numbers and not emotions, context, or vague instructions like humans do. But the data we often feed into AI models like text, images, or audio, isn’t made of numbers. It’s made of words, symbols, and context.
So here lies the challenge: How do we teach a machine to interpret our messy, vague, ambiguous language and turn it into something it can process and respond meaningfully?
To solve this, generative AI relies on a few clever concepts that bridge the gap between human language and machine understanding. Today, let’s explore the most important ones.
1. Text as Tokens :
Think of how you read a sentence. You don’t process it one letter at a time. Instead, your brain picks up chunks of words or phrases that carry meaning.
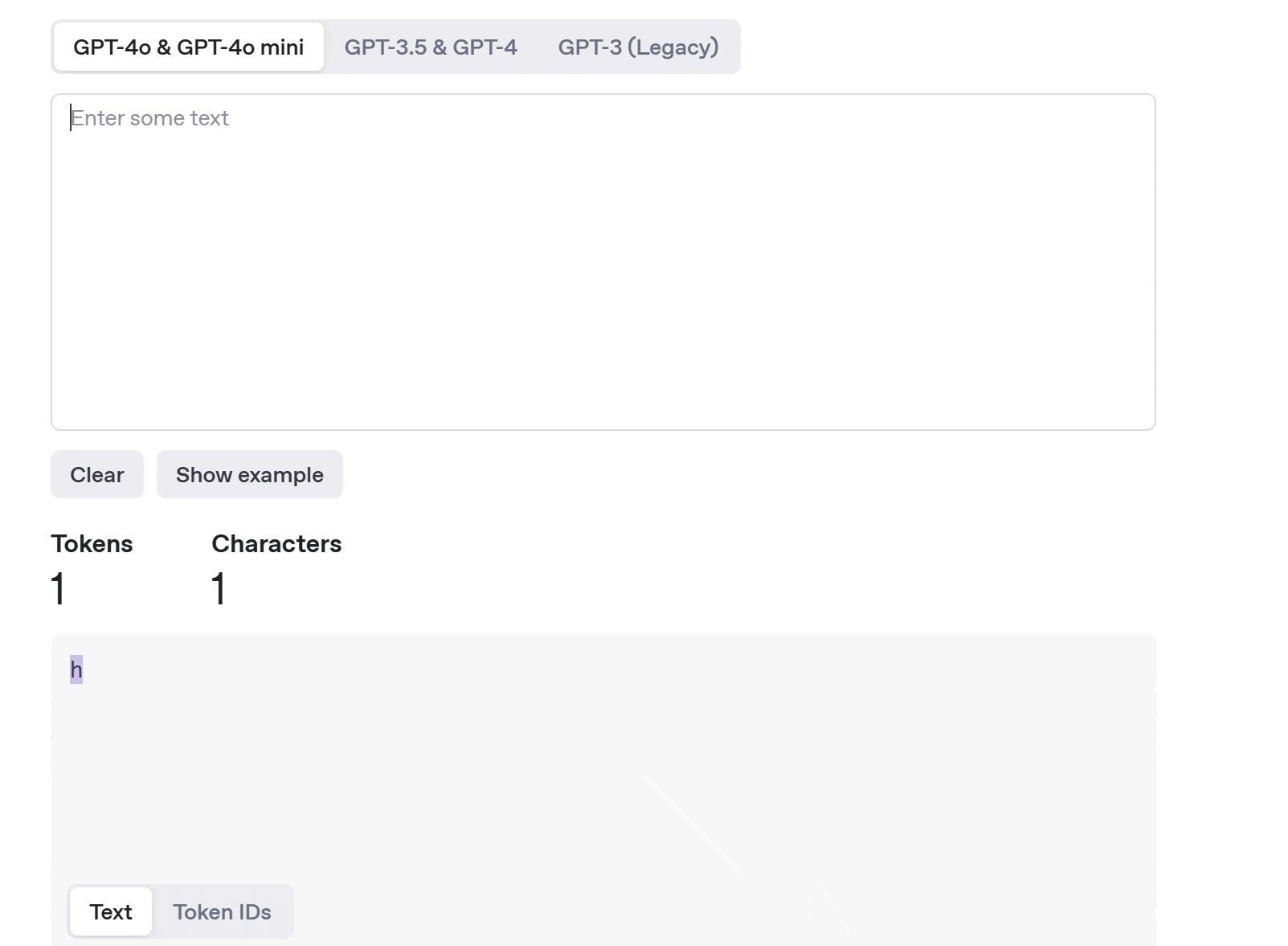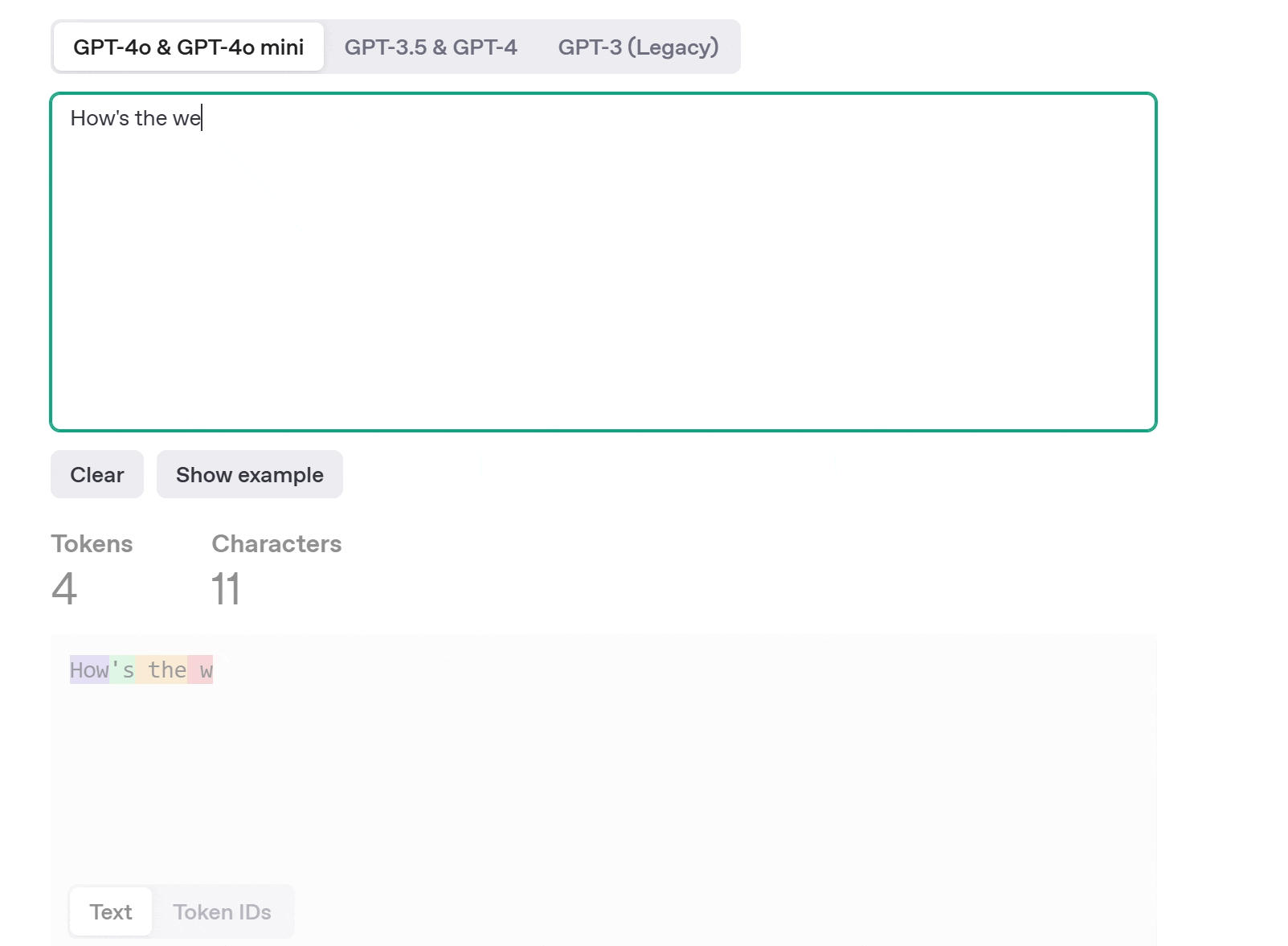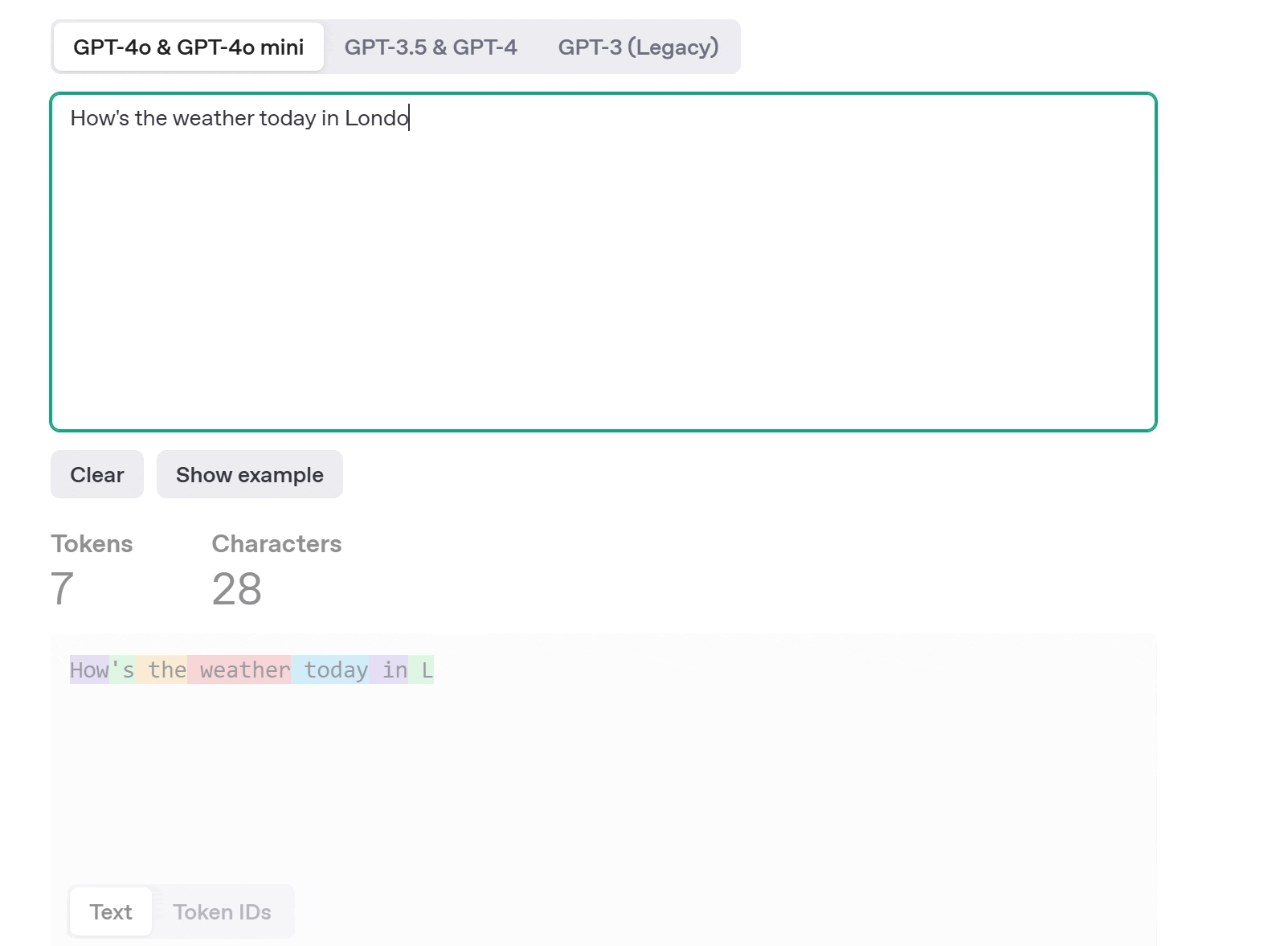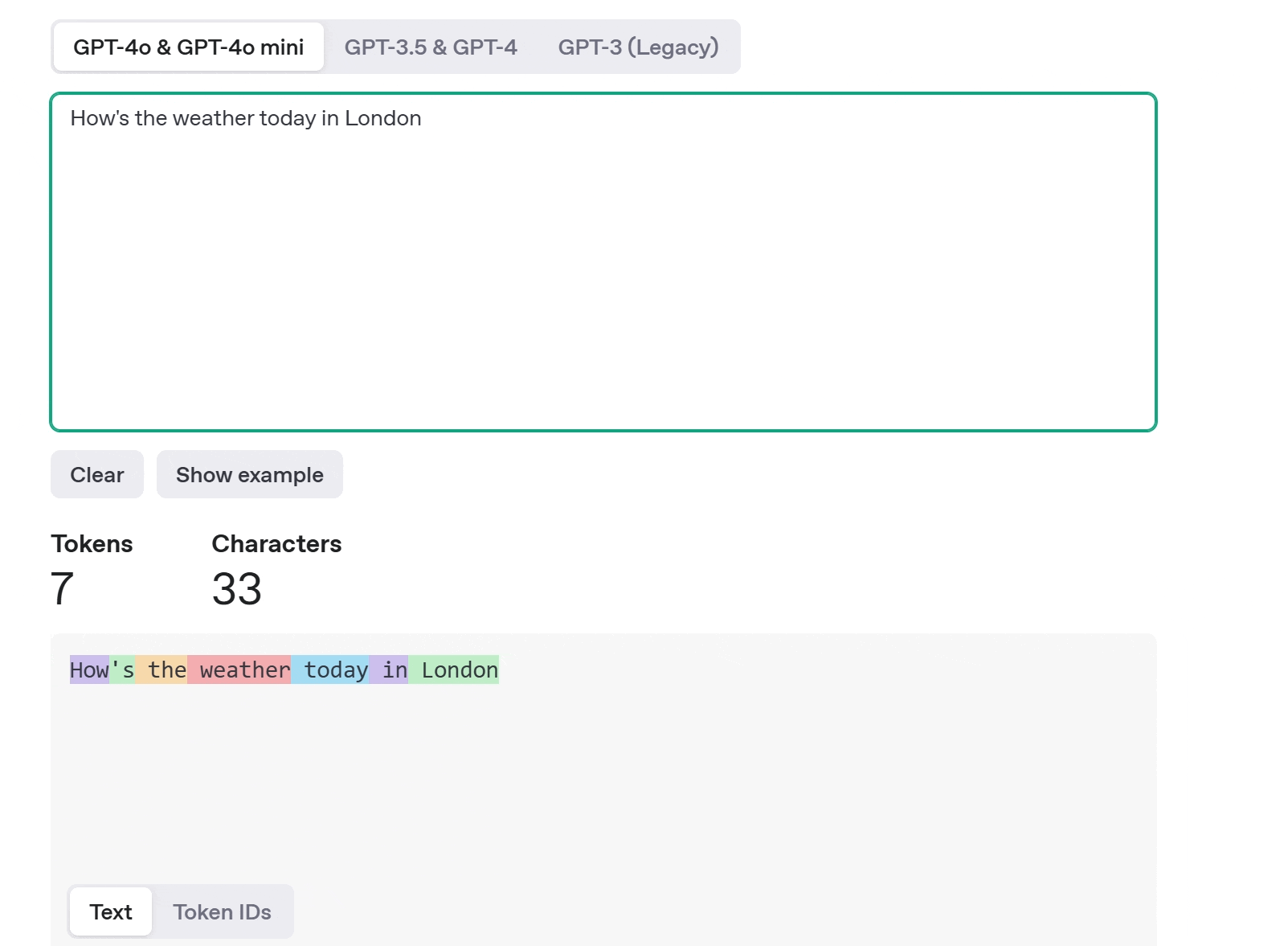
AI does something similar using tokens. A token can be a word, part of a word, or even punctuation. When you input a sentence like “How is the weather today in London?”, the model breaks it down into tokens, and it recognizes, often using statistical models to determine the most useful token boundaries. Look at the GIF. For the same sentence I have provided, it has broken down into 7 tokens.
Understanding tokens is essential because:
AI models operate at the token level, not on whole words or sentences.
Every response is a prediction of the next token based on the previous ones.
More complex or longer prompts = more tokens = more compute power and possibly higher costs.
2. Data as Vectors :
Once a piece of text is tokenized (split into smaller chunks like words or subwords), it still needs to be converted into a form that a computer can work with numbers. But not just any numbers. These numbers need to carry meaning.
That’s where embeddings come in.
An embedding is a numerical representation of a token in a high-dimensional space, or simply a vector representation of a token. You can think of it as placing each word on a 3D map, but instead of 3 dimensions, we might have 50, 100, or even 1,024 dimensions. Wow, that’s quite unimaginable, isin’t it?
The idea is:
Similar words should be placed close together.
Different or unrelated words should be far apart.

Let’s say we embed these three words:
“king” →
[0.42, 0.85, 0.15, ...]“queen” →
[0.40, 0.88, 0.17, ...]“orange” →
[0.91, 0.11, 0.54, ...]The embeddings for “king” and “queen” will be closer to each other because they share similar semantic roles (royalty, gendered nouns, human entities), while “orange” will be far off since it's a fruit.
Embeddings are so powerful that they allow models to understand relationships and generalize similar words. Also, they are not hardcoded. They are learned during training. A model looks at large volumes of text and gradually adjusts the vector values for each token so that words with similar context end up closer in the embedding space.
3. Similarities in Vector Space:
We now understand that all the text we input is broken down into pieces called tokens, and the tokens are further vectorized and placed on a kind of map in a high-dimensional space where each point (vector) represents meaning learned from context.
But what does this map help with?
Imagine this: you're looking at a huge galaxy, where every star represents a word, phrase, or concept. Words that are related or that often appear together in similar situations tend to cluster in the same region of this galaxy.
For instance:
“king”, “queen”, “prince”, and “royalty” might all live near each other
“spaghetti”, “pasta”, and “lasagne” form another cosy cluster
“downtown”, “suburb”, “neighbourhood” might orbit in the location-themed zone
Now, to measure how similar two ideas are, AI often uses one of the two techniques:
Cosine Similarity: Focuses on Direction
Cosine similarity asks: “Are these two concepts pointing in the same direction?”
It doesn’t care how far they are from the origin (i.e., how long the vectors are), just how closely aligned they are. If two vectors have a cosine similarity near
1, they are interpreted as perfectly aligned,0 meaning completely unrelated, and -1 meaning opposite directions.
Euclidean Distance: Focuses on Length (Distance)
Euclidean distance asks: “How far apart are these two concepts?
The smaller the distances, the more similar they are; larger distances indicate less similarity.
I had this question, now what if the angle is small but the distance is large? You must have had the same question, I know:
This means the vectors are pointing in nearly the same direction, but one is much farther away from the origin than the other.
Interpretation in Generative AI
If you're doing semantic search or prompt matching, cosine similarity says:
→ “‘good’ and ‘great’ are basically the same idea.”If you're doing clustering, visualization, or tracking vector movement, Euclidean distance says:
→ “‘great’ is a more intense or farther-out version of ‘good’.”
Wrapping Up
Understanding just a handful of core ideas like tokens, embeddings, and vector similarity can completely change how you interact with tools like ChatGPT or any other generative AI.
You don’t need to know how to build the engine to drive the car. But knowing when to shift gears makes the ride a whole lot smoother.
So the next time you're tweaking a prompt or wondering why your chatbot sounds stiff, you’ll know it might just be the embedding space, or how the model’s interpreting your words.