
CI/CD with Databricks Asset Bundles - Building the Understanding (Part 1)

Imagine you are launching a Rocket. Think of your data project like a rocket launch. You don’t just build a rocket and hit “Go”. You test every part, prepare carefully, and only launch when everything is ready.
That’s exactly what CI/CD (Continuous Integration / Continuous Deployment) does. It makes sure your Databricks code is tested, packaged, and safely launched to production.
And Databricks Asset Bundles (DABs) are like the rocket container that holds all your parts neatly together before the launch.
Why Use Bundles?
Without a bundle, deploying a project is like sending rocket parts in separate boxes. Pieces get lost, and someone might put them together wrong.
With a bundle:
Everything is organized and versioned
Multiple people can work together safely
You can automate testing and deployment using CI/CD
Your projects work the same way in dev, test, and prod environments.
What’s inside a Bundle?
A DAB contains everything your project needs, just like a rocket mission kit:
Python files: All your business logic
Jobs and pipeline settings: All the instructions for what tasks should be performed
unit and integration tests: Testing scripts that help you retest the code in different environments
Cluster and workspace configuration files: These files include cloud infrastructure settings, resource definitions, and workspace parameters.
All of this together makes the bundle complete, ready to move to different environments.
How does it work?
You define your bundle in a YAML file, specifying all the details where your Python files, jobs, unit tests, etc, are present in each environment.
You use databricks CLI to validate, deploy, and run the bundle via an IDE, your terminal, or directly on databricks.
Once deployed, your project runs consistently and reliably across all environments.
We need to use DABs when multiple people are working on the project, and also when you consider automation and CI/CD important.
Understanding CI/CD:
In modern data engineering and analytics, CI/CD (Continuous Integration, Continuous Deployment) is essential, making sure code changes are integrated swiftly, tested thoroughly, and deployed with confidence.

On the right is the classic CI/CD infinity loop. Let me walk through each stage in order.
Plan: Gather requirements, define tasks, and outline the system architecture. This blueprint guides all the next steps.
Code: Develop new features or update existing ones in a version-controlled environment. Every change is tracked in the version control system (VCS).
Build: The Continuous Integration server checks out the branch, installs dependencies, and compiles or packages the application into a versioned artifact.
Test: Automated pipelines run unit tests, formatting checks, and integration/end-to-end tests to ensure quality.
Release: A successful test run promotes the artifact to be ready for release
Deploy: We are now in a continuous deployment phase. The pipeline pushes the identical release into the target environment.
Operate: The application now runs live. All the metrics can now feed into dashboards, so you can exactly see how it behaves in real-world conditions
Monitoring: We set up alerts to capture any failures or errors. These flow back into your backlog, fuelling the next round of planning and closing the loop on continuous improvement
While we say Continuous Delivery and Continuous Deployment are the same, there is a slight difference between the two. Continuous Delivery pauses after the Release for human approval to deploy, whereas continuous deployment skips it. Continuous Deployment is fully automated.
Now that we have looked at the details of CI/CD and DAB. Let’s see what happens when we develop in Databricks without CI/CD
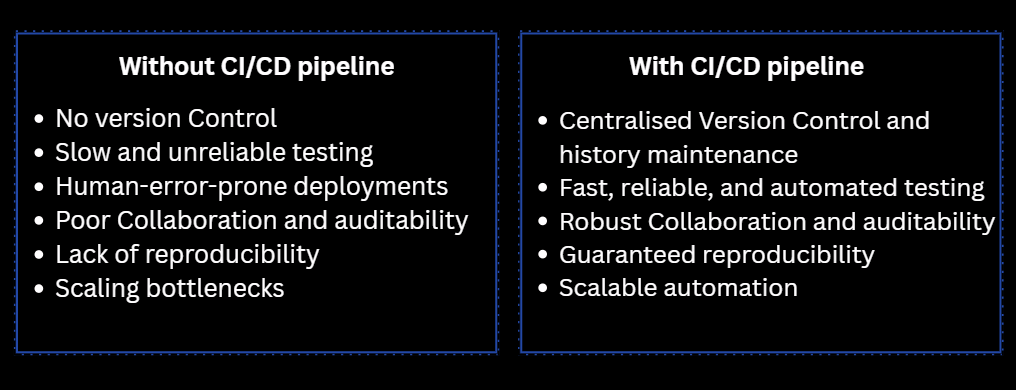
But do BI Teams really need CI/CD when they’re already consuming data from the Gold layer?
Even though you’re already querying the Gold layer, there are real risks if you don’t follow some best practices:
A new SQL change or join may break reports for stakeholders
Without version control, you can’t track changes to queries or dashboards over time
Multiple BI developers may overwrite each other’s changes
Without automated testing, a small change might cause incorrect KPIs or metrics
All of these factors may lead to an unreliable process, weakening the trust stakeholders place in the BI process.
How BI Teams can do lightweight CI/CD
BI Teams wouldn’t need a full Dev -> Prod pipeline like engineering teams, but you can adopt some best practices. Below are some of the best practices we follow in our team, which may help you, too
Source Control: Store your SQL queries, notebooks, and data models in a GitHub Repo or a Databricks Repo. This ensures every change is tracked and recoverable
Code Reviews: Use pull requests to review changes before they go live. This helps catch errors early and promote team collaboration
Test Environments: Always test any changes in your personal workspace or a folder dedicated to your testing that has test scripts before deploying it to production
Version Tracking and Documentation: Document your changes and maintain version history for full transparency. It helps others understand what changed, when, and why.
This is often referred to as “mini CI/CD” or a lightweight CI/CD for BI Teams. It doesn’t require any complex pipelines, just a structured way of managing a change.
Wrapping Up: CI/CD isn’t just a process. It’s a mindset for building trust, reliability, and consistency across your entire data value chain, from raw ingestion to final dashboards.
Databricks Asset Bundles give you the structure, and CI/CD brings the discipline to ensure every project launch is safe, repeatable, and scalable.
We’ve laid the foundation today by understanding why CI/CD matters and how DABs make deployment smoother.
In upcoming parts of this series, we’ll roll up our sleeves and build a working CI/CD pipeline for Databricks using Databricks Asset Bundles. You’ll see how to:
Validate and deploy a bundle using the Databricks CLI
Integrate GitHub Actions for automated testing and deployment
Manage environment-specific configurations seamlessly
Stay Tuned! Should you have any questions or just would like to connect, please reach out to me on LinkedIn! Until then, happy learning!