
Databricks - Auto Loader
What is Auto Loader?

Auto Loader in Databricks is a feature of Structured Streaming that simplifies and optimizes the ingestion of new data files as they arrive in cloud storage (such as S3, ADLS, Volume, or GCS) into Delta Lake tables. Auto Loader lets you scan a cloud storage and only ingest new data that arrived since the previous run. This feature is called incremental ingestion.
Important Features
Incremental File Ingestion: As mentioned earlier, it detects only new files that haven’t been processed before. Supports exactly-once processing when writing to delta tables.
Streaming and Batch Modes: Supports both Streaming and Batch modes. You can use Streaming mode for real-time pipelines and batch mode for large historical or one-time loads. You can seamlessly switch between both.
Schema Inference and Evolution: It automatically infers the schema on first load. It stores the schema in a dedicated path via cloudFiles.schemaLocation and supports automatic schema evolution.
Maintains the state via checkpointing: Imagine you are reading a huge stack of files into your delta tables, and suddenly, there is a disruption. Now, when everything comes back, how do I know where the ingestion left off? That’s exactly where checkpointing comes in. It’s like a bookmark or save point that Auto Loader keeps in a special folder. It remembers which files have been read, what the last record processed was, and what schema was used.
Let’s understand how with an example
For this demonstration, I will use Volumes instead of S3, GCS, or ADLS, as these are convenient and don’t require any mounting. It is ideal for demonstration purposes.
Let’s process the files using Auto Loader using Volumes
Step 1: Create Input Folder:
Create an input folder inside a volume. We simulate daily data arrival by creating date-based subfolders under volume (e.g., /2025/08/01/). This structure mimics real-world pipelines where files arrive daily in partitioned folders.

Step 2: Simulate Data Arrival
Since we don’t have external systems in this small demo, we mimic the process by manually adding CSVs (via pandas.to_csv() or Databricks file upload) to demonstrate how Auto Loader picks up only the newly added files. In an actual Auto Loader setup, those files would normally arrive in your landing folder automatically from upstream systems.
Step 3: Set Schema and Checkpoint Path
Set Paths for Auto Loader
schema_path: where the inferred schema is stored.checkpoint_path: where processing state is saved to ensure exactly-once ingestion.
schema_path and checkpoint_path can be the same or different.
Same path for small/simple demos.
Different paths when you want to isolate schema management from checkpoint metadata for operational reasons.
Now that the checkpoint path and schema path are already created, let’s understand how Auto Loader can detect new files:
Efficient File Detection:
Scanning folders with many files to detect new data is an expensive operation, leading to ingestion challenges and higher cloud storage costs.
To solve this issue and support an efficient listing, Databricks Auto Loader offers two modes:
Directory Listing
File Notification
Directory Listing: This is the most widely used and also the default mode. Directory Listing is simpler to set up (no cloud event services needed) but slower for very large directories. In this case, Auto Loader uses API calls to the cloud storage location to detect new files that arrive at different locations. It also manages all of this within its checkpoint location using a scalable option called RocksDB ("RocksDB is a high-performance embedded database that Auto Loader uses internally to track ingested files efficiently.")
File Notification: In this case, it uses Notification and Queuing services in the cloud account. So whenever a new file arrives in the cloud account. A notification service would put that in a queuing service, which would be consumed by the Auto Loader to detect the new files arriving. This is more scalable but requires enabling cloud event + queueing services
In both cases, it uses the checkpoint location to provide an exactly once scenario.
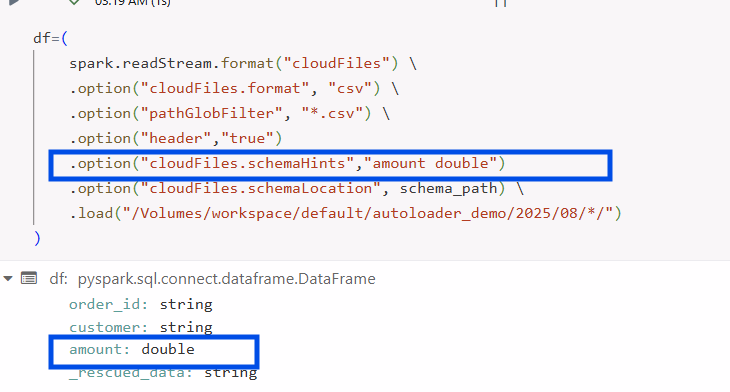
Step 4: Reading with Auto Loader
We configure spark.readStream to use Auto Loader’s cloudFiles format, setting the file type to csv. The recursiveFileLookup=true option enables Auto Loader to scan through our year/month/day folder hierarchy without needing explicit paths for each subdirectory. To further refine ingestion, we use pathGlobFilter to include only files matching a specific pattern (e.g., *.csv).
As we have already set the path for the schema location and checkpoint location, we will make use of those paths for schema storage.
You might need to enforce a part of your schema, e.g., to convert the amount to double in this example. This can easily be done with Schema Hints.
Let’s now write this dataframe to a delta table.
Step 5: Writing to a Delta table
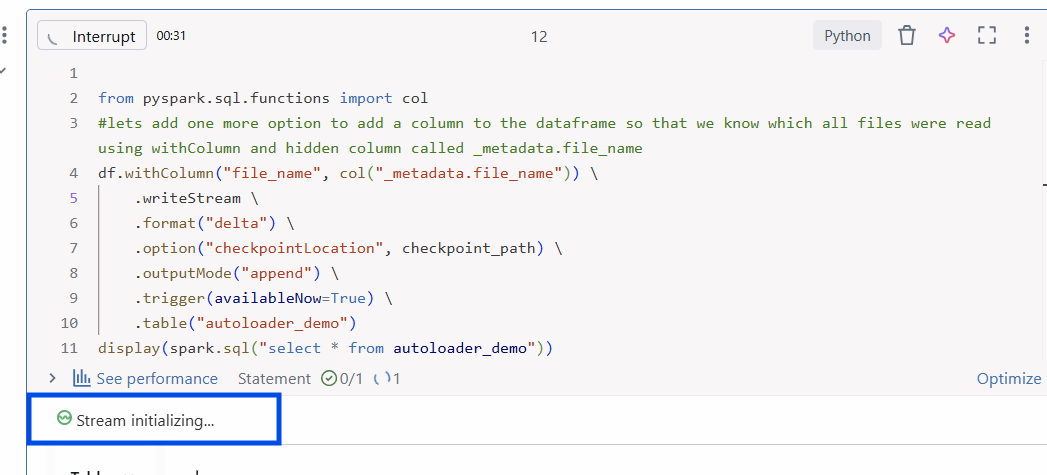
Let’s use writeStream to write data into a managed Delta table. The output mode is append, and the checkpointLocation ensures fault tolerance and prevents duplicate reads.
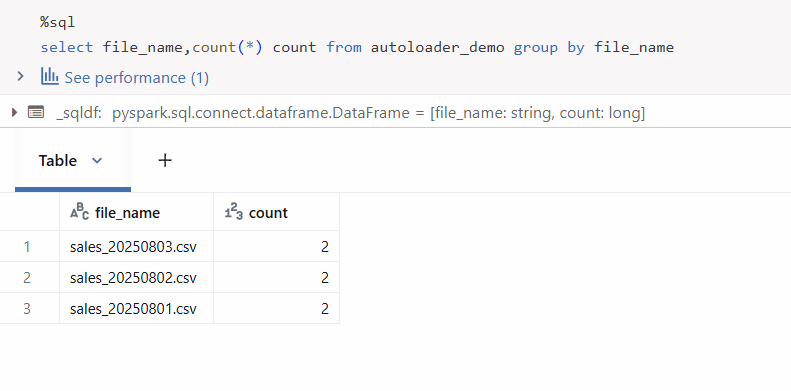
you can see that the table has been read in streaming mode, and the column values, for instance, amount, is double as mentioned earlier.
To ensure the files are not re-read again even after you run once more, you can make use of checkpoint location metadata (you should have higher access level privileges for that).
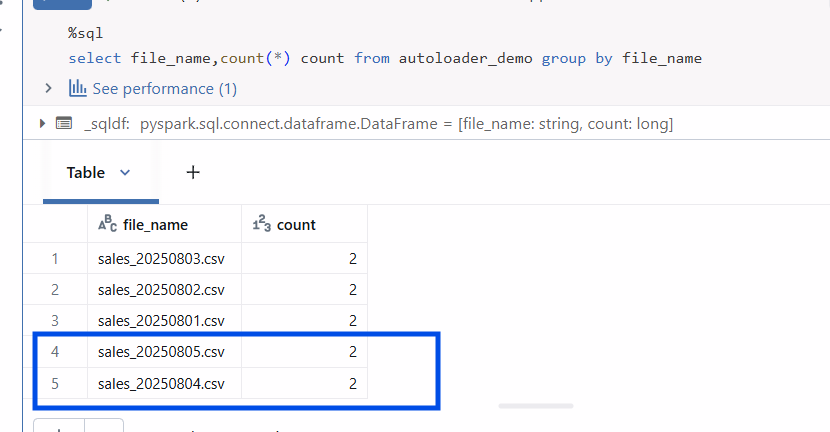
Step 6: Simulate Streaming
Each time we add a new CSV to a date folder, Auto Loader detects it (based on the trigger setting) and ingests it into the Delta table without reprocessing already ingested files.
I have now ingested files in the 04 and 05 date folders. Let’s see how it would trigger. You can see the new files have arrived into the delta table.
Wrapping up: Auto Loader simplifies incremental file ingestion into Delta tables with minimal setup, strong fault tolerance, and support for schema evolution. Whether you’re streaming daily files or loading historical datasets, it can scale from simple demos to production-grade pipelines. Full demo code is available here. Should you have more question please feel free to reach out here.