
Schema Evolution in Databricks
Schema Evolution is the ability of a data system to adapt to changes in the structure of the data over time without breaking existing pipelines or losing any historical data.
In Databricks, this means that your table can automatically handle:
Any new columns that are added in the source
Data types are being changed in the source
Columns are being missed in some loads
Any nested structures that are evolving (we won’t be covering in this scenario)
Today, I will walk you through a specific scenario that I encountered at work, a common yet often challenging scenario when working with data pipelines in Databricks.
The Problem:
At first glance, the requirement seemed simple:
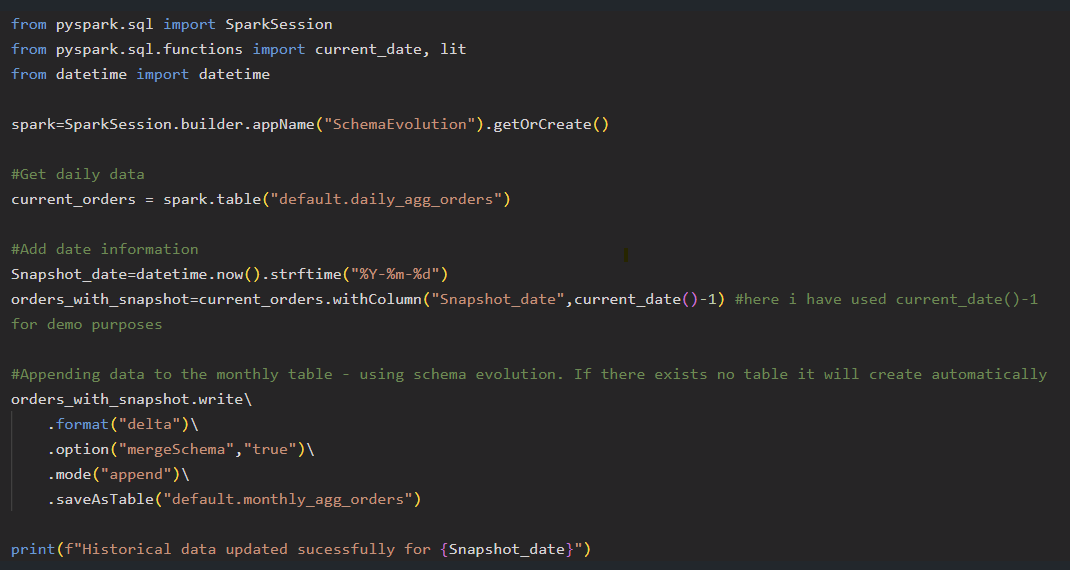
We maintain a daily Delta table that is overwritten with fresh data from the source system. On the first day of every month, we capture a snapshot of the current daily data and append it to a monthly table to help track trends and performance over time.
But here is the catch: the schema of the daily data is not fixed. Over time, we have seen the following changes:
New columns added
Existing columns removed
Data types modified( which may require a small manual adjustment in the code)
These evolving structures introduced the risk of breaking our snapshot logic.
This is where Delta Lake’s schema evolution support has been extremely helpful. By designing the job carefully and using Databricks' built-in features for schema evolution, we made the pipeline resilient to changes. This ensures that the monthly snapshots remain consistent and reliable, even as the structure of the incoming data evolves.
Brief Overview of Schema Evolution Scenarios
✅ Scenario 1: New Column Added in Daily Table
What happens:
A new column is added to the daily table.

How it's handled:
Delta Lake will automatically add the new column to the monthly table when mergeSchema is enabled during the write operation. No manual intervention is needed.
✅ Scenario 2: Column Removed from Daily Table
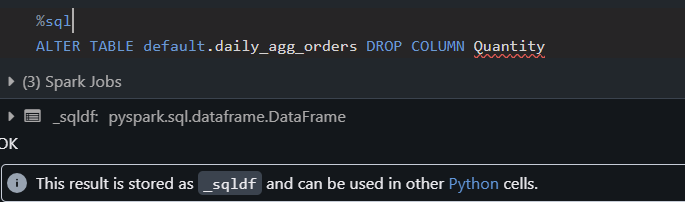
What happens:
A column is removed from the daily table (perhaps dropped upstream).
How it's handled:
When writing to the monthly table:
The missing column will appear as
nullin the new records.The column remains intact for historical record.
✅ Scenario 3: Change in a Column’s Data Type
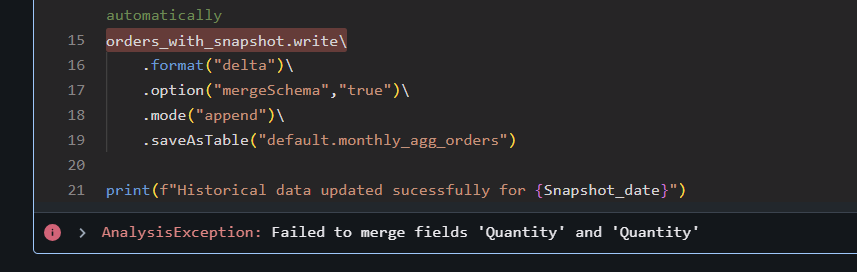
What happens:
A column that originally had one data type is now coming through with a different data type due to an upstream change in the source system.
How it is handled:
Delta Lake does not automatically handle data type changes. To avoid schema mismatch issues, you must manually cast(otherwise it will return an exception, please look at the screenshot) the column back to its expected data type .cast() before writing to the target table. This manual step helps ensure data consistency and prevents write errors caused by incompatible data types.
✅ Scenario 4: Change in the Order of Columns

Column Order Handling in Delta Lake:
In Delta Lake, column order does not impact data writes, as Delta Lake matches columns by name rather than by position. This means that even if the daily table and the monthly table have the same columns in a different order, the data is written correctly as long as the column names match.
This behavior is part of Delta Lake’s default functionality, not a schema evolution feature. When using methods like .write.saveAsTable, Delta Lake automatically aligns data to the correct columns by name, ensuring consistency between tables regardless of column order.
Wrapping Up:
In modern data pipelines, schema changes are bound to happen, especially when working with evolving source systems. Whether it is the addition or removal of columns, changes in data types, or structural adjustments, these changes can easily break downstream processes if not managed properly.
With the support of Delta Lake’s schema evolution features, you can build pipelines that are both resilient and future-ready. By enabling options like schema merging and applying manual steps when required, such as casting data types or renaming columns, you can maintain consistent and dependable snapshot logic.
Understanding these scenarios and planning for them in advance ensures that your data workflows remain stable even as the source data evolves. Schema evolution is a reflection of a dynamic and growing data ecosystem. With the right approach, your pipelines can adapt smoothly and continue to deliver reliable insights. Should you wish to look at the full code base, take a look here.