
Real-Time Weather Data Pipeline
Real-Time Weather Data Pipeline with Kafka, Python & PostgreSQL (Using Docker)
What are we building?
Imagine you’re building a dashboard that shows real-time weather updates. Maybe you want to analyze how temperature varies across cities, or trigger alerts when humidity hits extreme levels. To do that, you need a constant stream of fresh weather data and a place to store it for further processing.
We’re going to set up a system that:
Fetches live weather data using a public API
Streams it through Kafka (a high-speed messaging system)
Consumes it with another Python service
And finally, stores it into PostgreSQL
Why Apache Kafka?
Before diving into the how, let’s discuss the why. Why did I choose Apache Kafka over the other streaming platforms?
Kafka is built for real-time, high-throughput, fault-tolerant messaging.
Here’s what makes Kafka so powerful:
Scalability: Kafka handles high-throughput data like a pro. Even if your use case is small now, Kafka’s architecture prepares you for bigger workloads.
Reliability: Kafka stores messages for a defined period, even after they’re consumed, making reprocessing or debugging a breeze.
Decoupling: Kafka separates data producers from consumers. This means your weather API script doesn’t need to know or care where the data goes, it just pushes it to Kafka.
Flexibility: Want to plug in another consumer that sends email alerts? Or maybe one that visualizes weather trends on a dashboard? Kafka makes that easy without touching the producer.
Think of Kafka as the central nervous system of a data platform where messages flow in and out, and each piece does its job independently.
Architecture At A Glance
Here’s what the architecture looks like:
Kafka Producer: A Python script that connects to a public weather API, formats the data, and sends it to a Kafka topic.
Kafka Broker & Zookeeper: Kafka’s backbone handles and routes the messages.
Kafka Consumer: Another Python script that listens to the topic, processes the data, and writes it into a PostgreSQL table.
PostgreSQL Database: Our final destination for weather records, where they’re ready to be queried or visualized.
Docker Compose: Ties all the services together, making them easy to deploy and manage.
Getting the Data – The Kafka Producer
At the heart of any Kafka data pipeline lies the Producer, the component responsible for generating and sending data into Kafka topics.
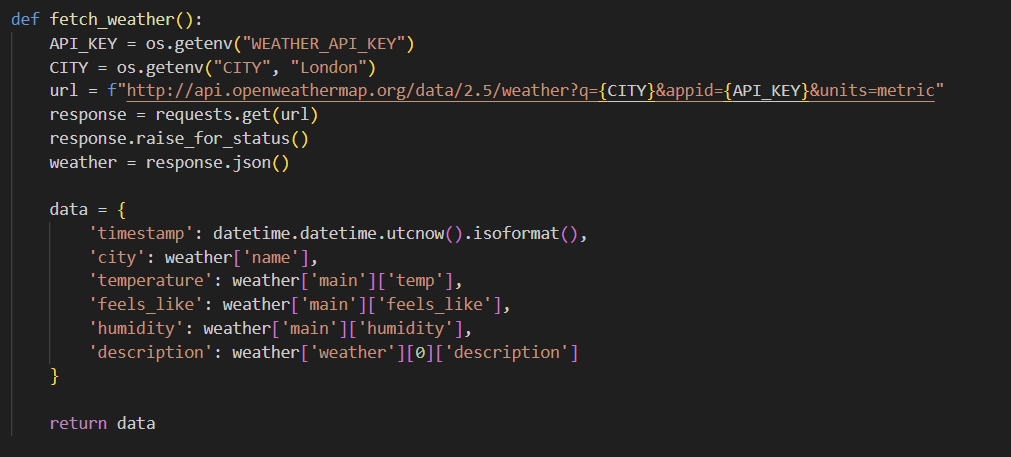
The producer plays a vital role by fetching real-time weather data from an external API. Every few seconds, it makes an API call to retrieve the latest temperature, humidity, and other weather metrics. This structured data is then serialized into JSON format and sent to a Kafka topic (in our case, a topic named "weather"). Think of it as a data dispatcher. It collects fresh data and pushes it to Kafka, which acts as the message broker.
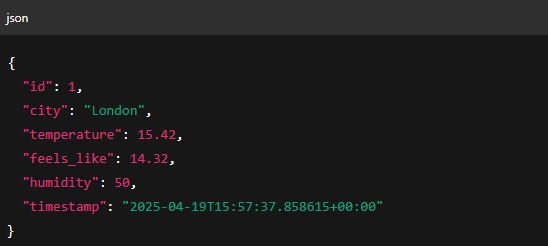
Here’s what our Producer is essentially responsible for:
Fetching live data: Instead of simulated/fake data, it retrieves real weather stats via an API.
Structuring the data: Formats it into JSON for consistency and easy consumption downstream.
Sending it to Kafka: Publishes the data to a Kafka topic, making it available to one or more consumers.
This process happens continuously on a schedule (e.g., every 60 seconds in my case), ensuring that downstream systems like our Kafka Consumer and PostgreSQL database always receive fresh data.
Here is the sneak peek of how the producer code looks:
Receiving and Saving Data: The Kafka Consumer
If the producer is the one sending the data, then the consumer is the one receiving and processing it. The Kafka consumer listens to the Kafka Topic(weather) for any new messages our producer publishes. As soon as the data arrives, the consumer picks it up, extracts the mentioned information, and inserts it into the PostgreSQL(in my case) database.
Here’s what our Consumer is essentially responsible for:
Listening to Kafka: The consumer subscribes to the “weather” (topic) and constantly monitors it for new incoming messages.
Reading and Deserializing: Once the new message has arrived, it reads the JSON-formatted data and deserializes it back into a Python dictionary for easy handling.
Storing the data: Kafka Consumer deserializes the data and inserts it into the PostgreSQL database.
Ensuring Reliability: By committing the Kafka message offset after processing, it ensures that no data is lost and that every event is stored exactly once.
Where does ensuring reliability happen in the code? :
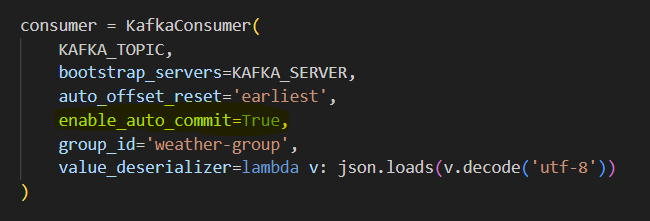
enable_auto_commit=True means:
After your consumer reads and processes a batch of messages, it automatically commits the offsets.
"Offset" is Kafka’s way of keeping track of how far a consumer has read the topic.
When an offset is committed, it’s saved in Kafka, so if your consumer crashes or restarts, it knows where to resume without re-processing old data.
Now, how does all of this work together?
Docker-compose.yml:
This YML file manages different services like Kafka, Zookeeper, Postgres, Producer, the Consumer, and lets them work together easily. You may probably run docker commands multiple times, even without this, but it will particularly simplify the run using just one bash command.
“docker-compose up”
And voila, the entire pipeline starts working.
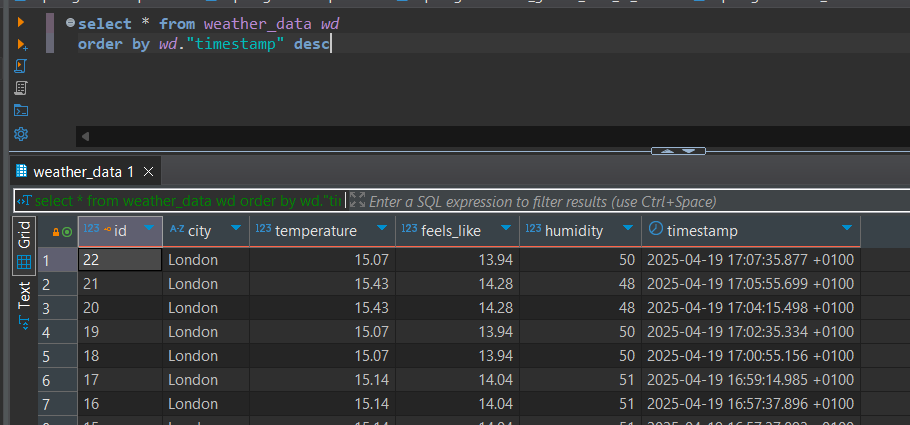
Verifying how it works
To check everything is flowing as expected:
Use
docker logs kafka-producerto see if weather data is being fetched.Use
docker logs kakfa-consumerto confirm it’s inserting into PostgreSQL.Use
psqlor a database client like DBeaver to runyour select queryand view records.
Key learnings:
We have seen how the real-time ingestion works, how data is processed on the fly, and how the database captures everything for future insights.
We could probably extend this nano project by:
Adding alerts if the temperature exceeds a certain threshold
combining it with any relevant data set
Visualising data on a live dashboard
Sending updates to the users based on the location.
Wrapping up:
If you are curious about streaming data or want to build your first data streaming pipeline, this is a great hands-on project to start with. A full working version of this project is available on my GitHub profile. Feel free to check it out, play around, and even extend it with your ideas!
Building something end-to-end from a real-time data producer fetching live weather, to a Kafka pipeline, all the way into a Postgres database, gives a solid understanding of:
How real-time systems work under the hood
Why Apache Kafka is the heart of modern data platforms
How important Docker and docker-compose are for managing microservices
How producers and consumers work together to move data reliably
Follow along as I continue to break down more real-world data projects in simple, beginner-friendly ways. There's so much more to explore!