
SQL Grader using LLM
Recently, I have completed a bootcamp program where we had to submit assignments, and instead of a human reviewing them, an LLM(Large Language Model) graded them!
Every time I submitted my work, the system would analyze, score, and give feedback almost instantly. It felt like magic, but it also made me wonder: How does this work behind the scenes? Can I build something like this myself? All these questions planted the seed for this nano project that evaluates and grades your SQL queries.
What does this project solve?
Learning SQL isn’t just about writing queries, it’s also about knowing whether your logic is right, and how can you improve.
In a traditional approach, you need mentors to manually check the code. But by using LLM, I realized we can automate grading and provide more personalized feedback based on the intent, not just syntax. This also makes learning more scalable and immediate.
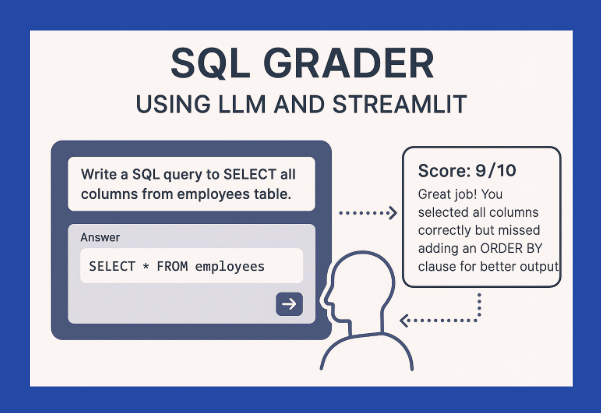
In this project, I have built a user interface that has an SQL questionnaire. The user is allowed to input the SQL scripts as the answers and the LLM evaluates the script and provides a detailed feedback.
Tech Stack :
Python
OpenAI API (gpt-3.5-turbo)
Streamlit
I have kept the stack minimal, accessible, and cost-effective, focusing on building the core logic first.
The User Interface :
For this, I have made use of Streamlit, a Python-based framework that allows you to create web apps quickly without needing any front-end knowledge.
Here’s what the user experience looks like:
The user would enter their name, for a more personalised touch- (don’t worry, none of the information is captured)
Every time a user visits, they are shown three random SQL questions out of a larger pool. This keeps the experience fresh and challenges them on different topics.
For each question, users are shown a sample table snapshot so they know what the underlying data looks like.
Users can type their SQL query in the text area provided and click on the submit button.
Upon submission, the app sends the user’s answers along with the expected correct answers to the LLM. While the LLM doesn’t have direct access to any live databases, it plays a powerful role. Instead of executing SQL queries against real tables, the LLM analyzes, compares, and scores the user’s submitted SQL purely based on textual reasoning.
Using the sample table structures and expected answers provided in the prompt, the LLM intelligently evaluates:
Whether the user's query logic matches the intended solution,
Whether the correct tables, columns, and conditions are used,
And whether the query achieves the same outcome even if phrased differently.
Here’s a video of how it works:
Under the Hood :
While the above app is the face the user interacts with, the Python script does the heavy lifting behind the scenes.
This script involves the core logic of the project. After the user submits their answers, their inputs are sent to this script, which takes: the user’s SQL query, the expected answer, and the sample data related to that question. We then ask LLM to act like a SQL expert and provide detailed feedback on different parameters. This script uses the OpenAI API to talk to the Large Language Model. After the analysis is done, it sends the feedback to the app, where the user can find all the detailed feedback.
What Next?
While this project already offers a powerful POC, there are many exciting directions this can grow:
We could probably spin- up a temporary database instance, execute both expected query and the users query and compare actual result set for a 100% objective match.
Right now, I have randomized the questions. Probably, we can adapt to the user’s performance. Like, you can start with easier questions first, and based on the performance, you can increase or maintain the difficulty level.
Not just SQL, but educational systems(probably some are already leveraging it) can adopt to create students learning profile etc.
Wrapping Up:
What I started was a simple exploration after the BootCamp project, wondering how LLM-based grading works, which has now evolved into a scalable idea. Thank you for taking the time to walk through this nano project with me. The full working version of the project is in my Github profile for you to explore, add new ideas.