
Real-Time Crypto Price Tracker using Databricks
One day, while watching Bitcoin prices fluctuate, I wondered if I could track those prices in real time with no cost! It turned out, I can. For this simple nano project, I have used tools that are readily available at no cost, purely for experimentation and learning. The idea is to build a lightweight and efficient setup that lets us observe Bitcoin price movements live, without needing a paid API or expensive infrastructure. This project is ideal for anyone who wants to get hands-on with real-time data tracking and understand how streaming works through accessible and open-source technologies.
What does this project solve?
Here’s What I Wanted to Build
Collect real-time price data of Bitcoin and Ethereum from the CoinGecko API
Store it in Databricks File System (DBFS)
Build a Structured Streaming pipeline that
Continuously reads new data
Is fault-tolerant using checkpoints, ensuring that even if the streaming job fails or restarts, no data is lost, and processing resumes from where it left off
Writes the processed data to a Delta Lake table, enabling efficient storage, versioning, and time travel
Is fully queryable with SQL, so we can explore the data in near real time, run aggregations, and build dashboards if needed.
This setup gives us a practical foundation to work with live data streams robustly and cost-effectively. It also introduces core concepts like incremental processing, schema enforcement, and recovery mechanisms all essential for building reliable data pipelines in the real world.
Incremental Processing:
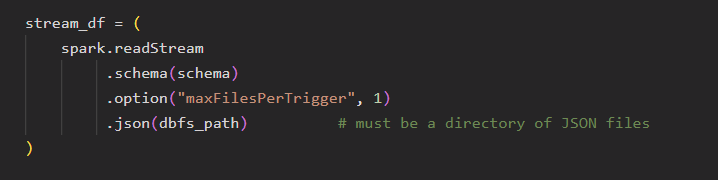
This is the heart of structured streaming. I have used a script that writes a new JSON file to DBFS each time it runs. For demonstration purposes, this is not scheduled, but in a real-world project, you would schedule this as a streaming job. The streaming job is configured to process only newly added files. As a result, only fresh data is ingested, and there is no need to reprocess old files. This approach reduces compute costs and ensures near real-time results with minimal lag. The maxFilesPerTrigger option controls how many new files Spark processes in each micro-batch. Since we are reading from DBFS, which acts as a folder of static files, this setting helps simulate file-by-file ingestion, effectively mimicking real streaming behavior.
Schema Enforcement:
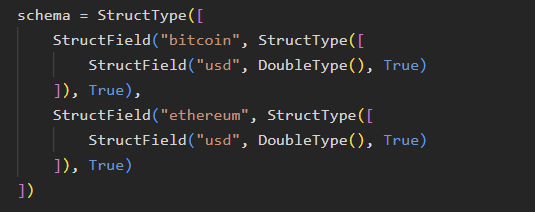
Real-time data often breaks when the schema changes. To prevent this, we define the schema explicitly. This ensures a consistent structure across micro-batches, avoiding surprises caused by nulls or missing fields. It also reduces unnecessary inference overhead and enables schema evolution strategies to be implemented cleanly. As a result, downstream tables remain reliable and cost-effective to maintain in production.
Fault Tolerance:
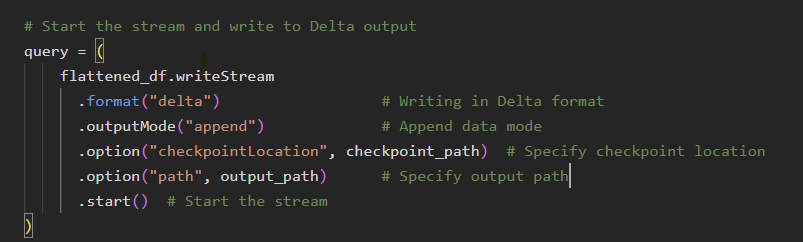
Imagine your pipeline stops midway. Do you want to restart from scratch or continue from where you left off?
That’s where Fault tolerance comes in. Fault tolerance is a critical aspect of any reliable streaming system. In Spark Structured Streaming, this is achieved by using a checkpoint directory. The checkpoint keeps track of the progress of the stream, such as which data has already been read and processed. This ensures that if the stream is interrupted or restarted for any reason, it can resume from where it left off without processing the same data again or missing records. In this project, I have used a DBFS path to store the checkpoints, which helps maintain data consistency and enables exactly-once processing semantics even in the event of a failure.
Why I Used DBFS (and Not Auto Loader)
You might ask why are you writing files to the Databricks File System (DBFS), instead of using a message broker like Kafka or tools like Auto Loader?
Auto Loader is great for handling large-scale data ingestion and streaming in production environments. It is specifically designed to automatically discover and process new files as they arrive in cloud storage, such as Azure Data Lake or S3. This makes it a perfect choice for event-driven architectures where real-time data processing is crucial.
With Auto Loader, you can streamline the ingestion of structured and semi-structured data without worrying about manually tracking or managing file paths. It offers built-in features like schema inference, data deduplication, and fault tolerance, ensuring reliable and efficient processing. Additionally, Auto Loader integrates seamlessly with Delta Lake, providing robust data management features such as ACID transactions, time travel, and data versioning.
However, its requirement for cloud object storage means that it’s not available for free in the Databricks Community Edition. And so, for my nano project I had to use the DBFS approach.
What I'd use in production:
Kafka or Event Hub for ingestion: These message brokers are suited for handling high-throughput, real-time data streams in production. This is also demonstrated in my previous nano project.
Auto Loader for automatic schema evolution and file detection: In a cloud-based production environment, Auto Loader can seamlessly handle real-time file ingestion and manage schema changes.
ADLS/S3/GCS as cloud-native storage: These storage systems are designed to handle the scale and performance required for production-level data pipelines.
What I Learned
You can build real-time data pipelines without spending a penny
Fault tolerance, schema enforcement, and incremental processing are not optional, they’re foundational
Delta Lake + Databricks gives a production-grade feel, even on Community Edition
Conclusion
This project taught me the importance of fault tolerance, schema enforcement, and incremental processing in streaming data systems. It also showed that with the right tools, even a small-scale setup can grow into something powerful, laying a strong foundation for future improvements and larger projects.
Should you wish to continue building on top of this project or try it out yourself, feel free to use the GitHub code available here. It’s a great starting point for experimenting with real-time data pipelines using Databricks Community Edition. I hope you enjoyed learning!