
Gen AI Made Simple: Understanding RAG and Instructed Retrieval (A Databricks Perspective)
In the previous part of the Gen AI Made Simple series, we explored how to communicate with large language models using practical prompt engineering techniques that anyone can apply. In this blog, let’s take the next step. Instead of just improving how we talk to the model, we’ll learn how to help the model talk more accurately back to us using our own data.
We’ve all experienced moments when Gen AI feels incredibly smart, yet doesn’t give the precise information we’re looking for. And that’s expected. An LLM can only respond based on the knowledge it was trained on. It doesn’t automatically know your company’s details, your processes, or your business context. So the answers often end up being generic.
But imagine if you could give the model access to your company’s documents, policies, or domain-specific knowledge, and it could retrieve exactly what it needs before answering your question. Suddenly, the model becomes not just smart, but context-aware.
That shift from generic answers to context-aware responses is where Retrieval Augmented Generation (RAG) comes in. This is also referred to as traditional RAG or Vanilla RAG.
At its core, RAG is a simple idea. Before the model answers your question, it first looks up relevant information from a trusted knowledge source that you have provided. The retrieved information is then passed to the model as context, allowing it to generate answers grounded in your data rather than general internet knowledge.
Understanding RAG:
Most basic RAG systems follow a fairly standard pattern.
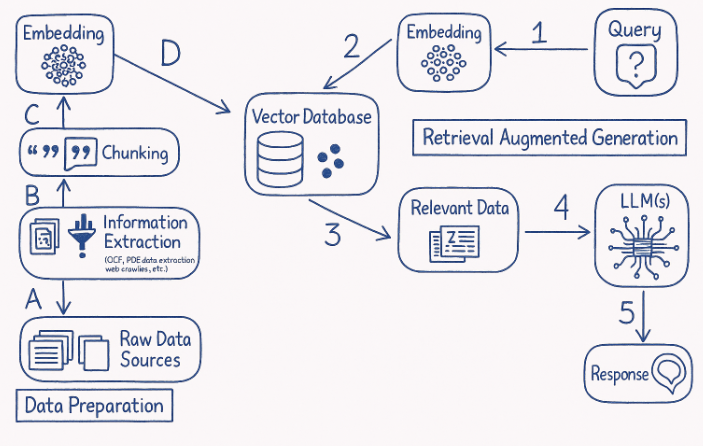
Simple RAG flow chart
Here’s how it usually works:
Your documents are broken into chunks.
Each chunk is converted into embeddings and stored in a vector database.
When a user asks a question, the system performs a similarity search to find the most relevant chunks.
Those chunks are sent to the LLM along with the question.
The model generates an answer based on that retrieved context.
This approach works surprisingly well and is a great starting point. It’s simple, intuitive, and easy to reason about.
The Reality:
However, as teams begin to use RAG in real business scenarios, some limitations become apparent. In fact, when I was testing RAG on Databricks, I noticed that some of the answers it returned were a little unrelated or didn’t fully match the question. This happens because RAG retrieves documents based solely on semantic similarity, rather than the intent behind the question. The model tries to fill in the gaps during generation, which can sometimes lead to answers that feel confident but aren’t fully accurate.
It retrieves documents that sound related, but it doesn’t always understand:
what “recent” means
what should be excluded
which metadata actually matters
Moving Beyond Similarity: Instructed Retrieval
Databricks introduces the idea of Instructed Retrieval to address this exact gap.
Instead of treating retrieval as a blind similarity search, instructed retrieval uses the model itself to guide how retrieval should happen.
In simple terms:
The model first understands what kind of question is being asked.
Based on that understanding, it decides what type of information would be most useful.
Retrieval is then guided by these instructions, not just raw similarity scores.
So retrieval becomes intent-aware, not just text-aware.
This is a subtle but powerful shift. Retrieval is no longer a passive lookup step; it becomes an intelligent part of the reasoning process.
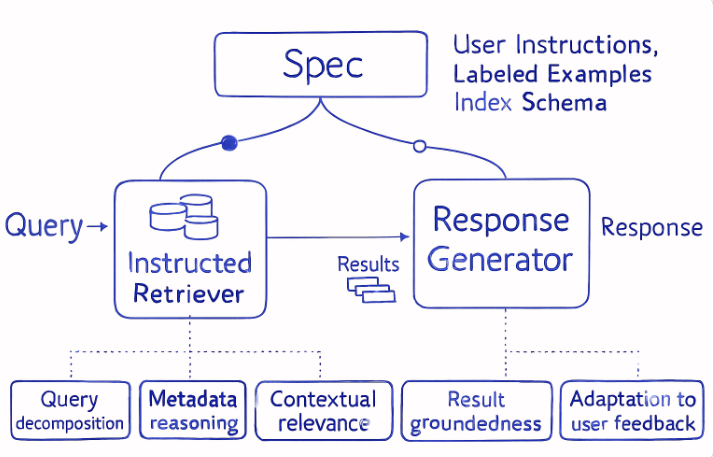
Instructed Retrieval Architecture
Architecture of Instructed Retrieval:
Step 1: The user asks a question, along with implicit instructions such as preferred data sources, recency, and response style.
Step 2: The system first understands what the user is really asking and plans how to retrieve the right information, instead of searching blindly.
Step 3: The original question is broken into smaller, structured search queries with clear filters and constraints.
Step 4: Relevant documents are retrieved based on intent and instructions, not just keyword or embedding similarity.
Step 5: The Metadata Reasoning, Natural language instructions (like “recent” or “exclude certain products”) are translated into precise metadata filters.
Step 6: Only instruction-aligned and relevant information is selected and prepared for the model to use.
Step 7: The model generates a concise and accurate answer, grounded entirely in the retrieved context and user instructions.
Where does Databricks implement the Instructed Retriever Architecture?
Databricks applies the Instructed Retriever approach within its Agent Bricks product suite(which is still in beta), especially in the Knowledge Assistant agent. This is a chatbot-like tool that:
Answers questions using your domain data
Follows user instructions and constraints during retrieval
Produces grounded, relevant answers based on enterprise knowledge sources
In this setup, the retrieval system doesn’t just find text that looks similar to a query, it uses instruction-aware logic to fetch the most relevant and intended information before generating a response. This leads to higher accuracy and better alignment with user intent than vanilla RAG alone.
Wrapping Up:
I hope this helped you build a clear understanding of what traditional (or vanilla) RAG looks like, where it starts to fall short in real-world scenarios, and how Databricks introduces the concept of Instructed Retrieval to address those gaps. In a future hands-on session, we’ll explore how these ideas come to life using Databricks Agent Bricks and see how instructed retrieval works in practice when building real Gen AI assistants.
There’s more to come in the Gen AI Made Simple series. Until then, stay tuned!!